New paper 🚨
Can we solely rely on LLMs’ memories (eg replace search w ChatGPT)? Probably not.
Is retrieval a silver bullet? Probably not either.
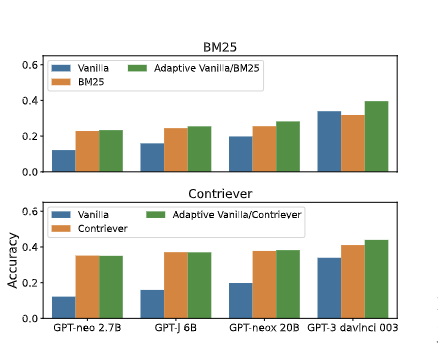
Our analysis reveals that LLMs' memorizations are still limited and scaling won't help much in long-tail distributions.
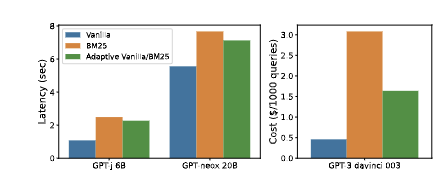
We show that adaptively incorporating non-parametric memories (eg retrieved chunks) can improve performance as well as efficiency.
📜 http://tinyurl.com/2sdeuupn 💻 http://github.com/AlexTMallen/adaptive-retrieval
#PaperThread #newpaper
[1/N]