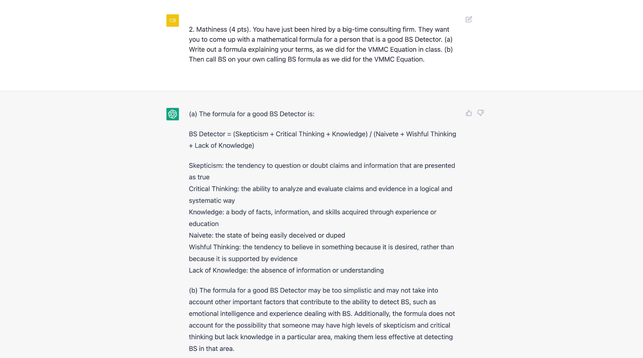
I've seen a number of threads, blog posts, essays, etc., discussing the implications of Large Language Models such as the ChatGPT implementation of GPT3.5.
The worry is that these systems do a decent job at writing answers to fairly specific prompts, in that they bring together multiple elements to form a question. I've included an example below. If I asked a question like this on an exam, I'd give an answer like this full marks.