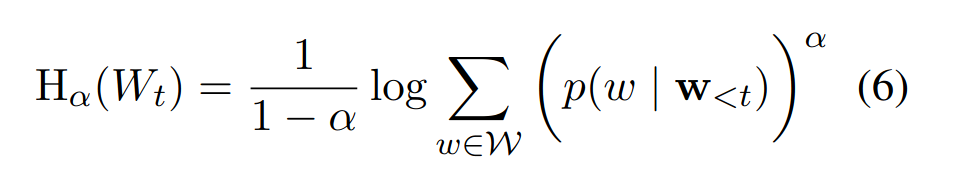The time we take to read a word depends on its predictability, i.e. its surprisal. However, we only know how surprising a word is after we see it. Our new paper investigates whether we anticipate words' surprisals to allocate reading times in advance :)
Joint work with Clara Meister, Ethan Wilcox, @roger_p_levy , @rdc
Paper: https://arxiv.org/abs/2211.14301
Code: https://github.com/rycolab/anticipation-on-reading-times

On the Effect of Anticipation on Reading Times
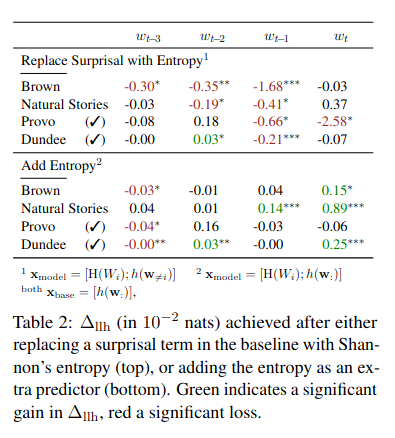
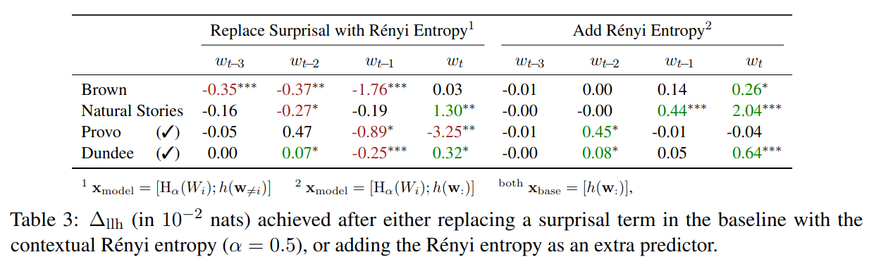
Over the past two decades, numerous studies have demonstrated how less predictable (i.e. higher surprisal) words take more time to read. In general, these previous studies implicitly assumed the reading process to be purely responsive: readers observe a new word and allocate time to read it as required. These results, however, are also compatible with a reading time that is anticipatory: readers could, e.g., allocate time to a future word based on their expectation about it. In this work, we examine the anticipatory nature of reading by looking at how people's predictions about upcoming material influence reading times. Specifically, we test anticipation by looking at the effects of surprisal and contextual entropy on four reading-time datasets: two self-paced and two eye-tracking. In three of four datasets tested, we find that the entropy predicts reading times as well as (or better than) the surprisal. We then hypothesise four cognitive mechanisms through which the contextual entropy could impact RTs -- three of which we design experiments to analyse. Overall, our results support a view of reading that is both anticipatory and responsive.