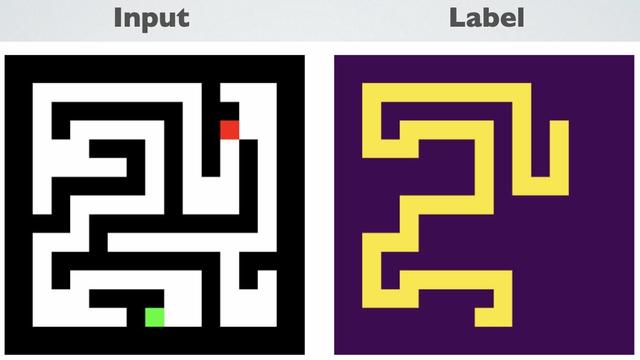
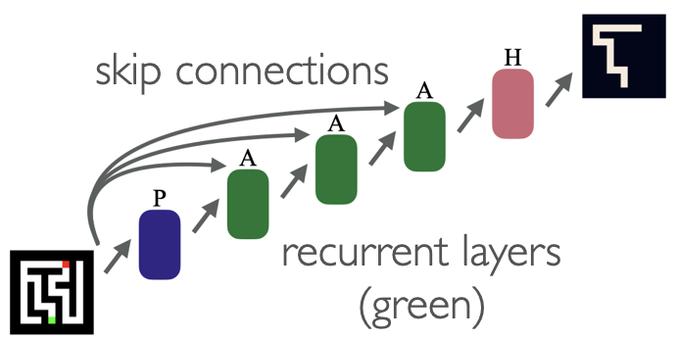
Neural algorithm synthesis is done by giving models a human-crafted programming language and millions of sample programs. Recently, my lab looked at whether neural networks can synthesize algorithms on their own without these crutches. They can, with the right architecture. 🧵