New blog post on the NeurIPS'21 experiment re authors' perceptions of their own papers!
https://blog.ml.cmu.edu/2022/11/22/neurips2021-author-perception-experiment/
Key findings:
1) Authors significantly overestimate their papers' chances of acceptance. By like a LOT.
>
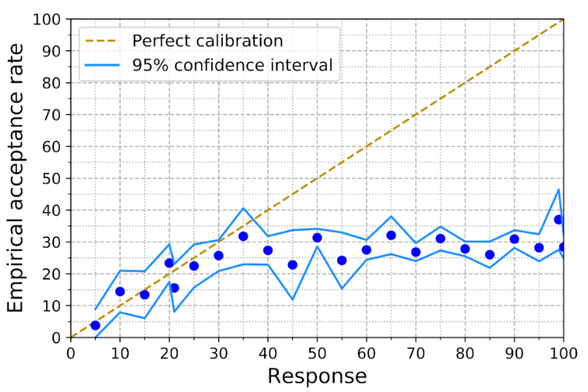

How do Authors' Perceptions about their Papers Compare with Co-authors’ Perceptions and Peer-review Decisions?
Alina Beygelzimer, Yann N. Dauphin, Percy Liang, Jennifer Wortman Vaughan(NeurIPS 2021 Program Chairs) Charvi Rastogi, Ivan Stelmakh, Zhenyu Xue, Hal Daumé III, Emma Pierson, and Nihar B. Shah There is a considerable body of research on peer review. Within the machine learning community, there