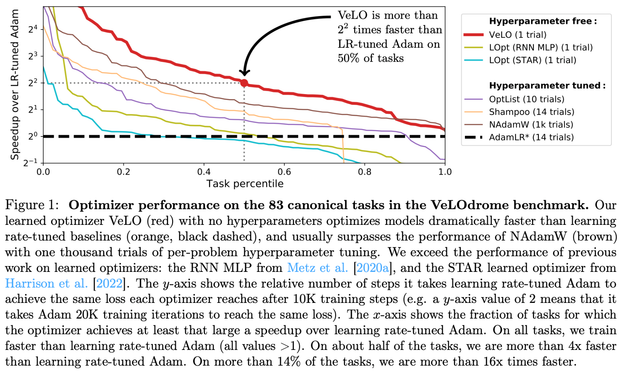
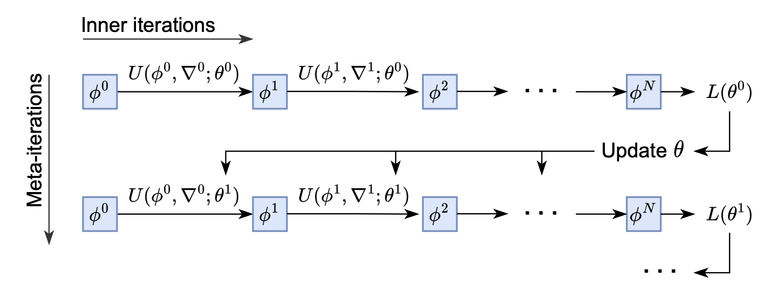
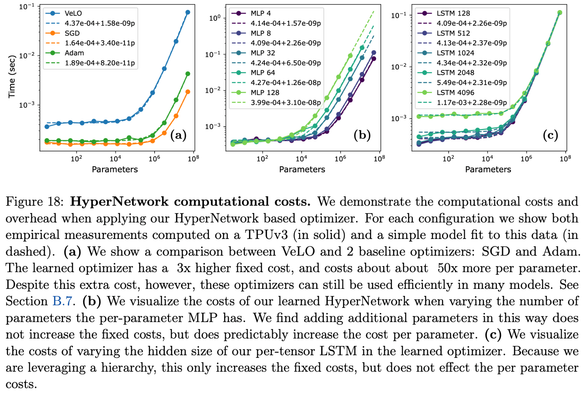
If there is one thing the deep learning revolution has taught us, it's that neural nets will outperform hand-designed heuristics, given enough compute and data.
But we still use hand-designed heuristics to train our models. Let's replace our optimizers with trained neural nets!
But we still use hand-designed heuristics to train our models. Let's replace our optimizers with trained neural nets!