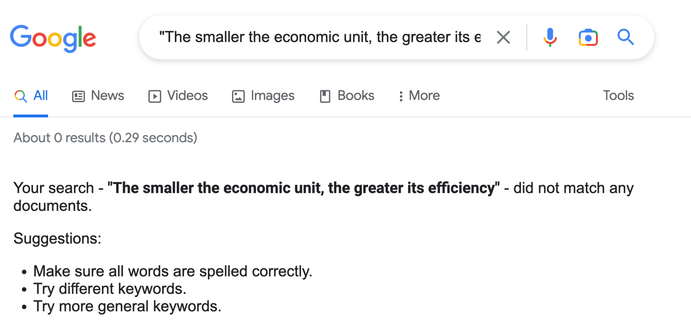
I've figured out what pisses me off so much about Facebook's Galactica demo.
It's not because people can use to to write bad essays for their homework. There are plenty of large language models that can do that. It's because Facebook is presenting it as something that it most definitely is not.
Facebook is selling it as a knowledge engine, a "new interface to access and manipulate what we know about the universe."
Actually it's just a random bullshit generator.