I am looking at Dagobah today, a Data-centric Meta-scheduler from @NetflixEng. This is a 🧵 summarising it.
P.S: This is part of the reading I am doing into schedulers these days. Watch this space for more.
I am looking at Dagobah today, a Data-centric Meta-scheduler from @NetflixEng. This is a 🧵 summarising it.
P.S: This is part of the reading I am doing into schedulers these days. Watch this space for more.
Motivations:
1. Need for data-centric pipelines emphasizing traceability, predictability, provenance, and structural sharing.
2. Encourage fine-grained, testable, functional computations. (a.k.a. transformations as pure functions).
3. Compose pipelines from multiple resources (Docker, Spark, Hive, etc).
4. Version-controlled, API centric configuration.
5. Resilience against job failures and restarts.
Salient Features:
1. The pipelines are initiated as user-requests for materializing leaf nodes in a DAG.
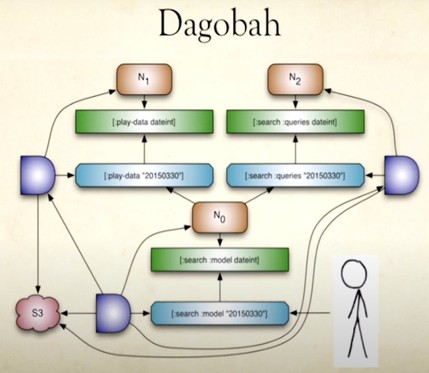
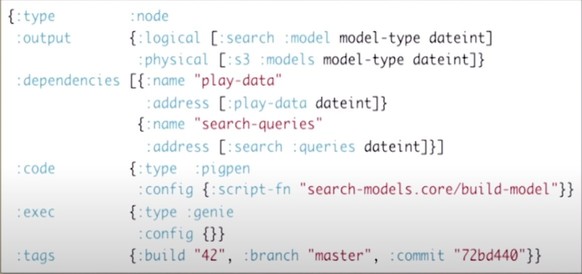
3. A node describes a data-dependency by listing the address of the data it needs.
4. The node points to the code to run (could be Spark code, Pigpen script, etc). The code itself is not part of the node definition. Thus, separating concerns of orchestration and computation.
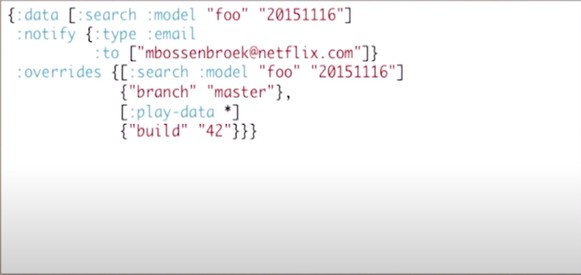

The other add-on features provided by Dagobah are:
- Gates: conditional materialization if error-thresholds etc are hit. This is based on user-input.
- Actions: Another way to control conditional materialization; this one does not need user intervention.
