ActiveRecord와 neighbor 젬을 활용한 벡터 검색: 문서당 최대 결과 수 제한 및 성능 최적화
PostgreSQL의 pgvector와 neighbor 젬을 사용하여 RAG 시스템 구축 시 결과의 다양성을 확보하기 위해 문서당 청크 수를 제한하는 SQL 최적화 기법을 제안합니다.
ActiveRecord와 neighbor 젬을 활용한 벡터 검색: 문서당 최대 결과 수 제한 및 성능 최적화
PostgreSQL의 pgvector와 neighbor 젬을 사용하여 RAG 시스템 구축 시 결과의 다양성을 확보하기 위해 문서당 청크 수를 제한하는 SQL 최적화 기법을 제안합니다.
AI 기반 오픈소스 밈 검색 엔진 'meme-search': Rails 8과 Python의 결합
AI를 활용해 이미지의 내용과 텍스트를 분석하고 벡터 임베딩을 생성하여 시맨틱 검색이 가능한 오픈소스 밈 검색 엔진이다.
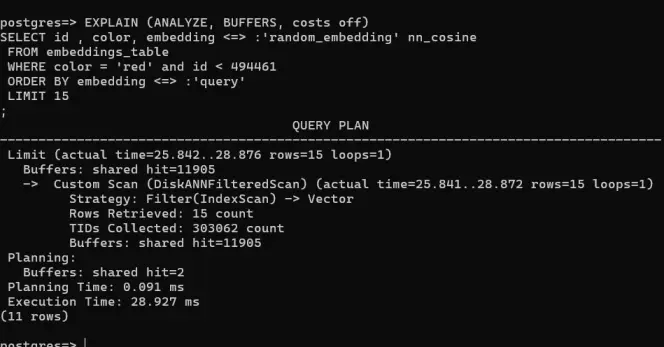
The vector-in-Postgres question for teams at scale: pgvector HNSW, which is on RDS, or pgvectorscale's StreamingDiskANN, which is not.
pgvector 0.8.2 also ships halfvec quantization for roughly half the storage at minimal recall loss. That changes the math before you reach for a separate index.

Most AI apps on #PostgreSQL are still in experiment mode. Getting to production means solving three specific problems: security hardening, grounded responses, & token efficiency.
Mike Josephson covers the open-source stack: MCP Server, vectorizer, RAG Server with hybrid pgvector + BM25 search, & docloader. Today's PostgresWorld session, 1 PM EST.
All tools PostgreSQL-licensed. No re-platforming, data sovereignty intact.
Register: 👉 https://postgresconf.org/conferences/postgresworld_webinars_2026/tickets

🚀 Picking a vector database for your AI app? Let's break down the top 3! 🧠
🌲 Pinecone = zero ops, high cost
🦭 Milvus = open source, massive scale
🐘 pgvector = keep it simple with Postgres
Don't overcomplicate your stack! Choose based on your scaling needs and engineering bandwidth.
#VectorDB #AI #Pinecone #Milvus #pgvector #dougortiz
📌 Let's connect: https://www.linkedin.com/in/doug-ortiz-architect/
▶ YouTube: @techbits-do
🌐 Bio: https://bio.site/dougortiz

Postgres 벡터 인덱스 선택 가이드: HNSW, IVFFlat, DiskANN의 트레이드오프 분석
데이터셋 규모와 메모리 가용량에 따라 HNSW(메모리 내 고성능), IVFFlat(저비용/쓰기 최적화), StreamingDiskANN(디스크 기반 대규모 데이터) 중 적합한 인덱스를 선택해야 한다.
RAG on Rails: Ruby on Rails를 활용한 검색 증강 생성 시스템 구축 가이드
Rails 8.1.1과 PostgreSQL의 pgvector를 활용하여 별도의 Redis나 복잡한 ML 인프라 없이도 강력한 RAG 시스템을 구축할 수 있음을 입증합니다.
Rails에서 pgvector를 활용한 시맨틱 검색 구현 가이드
키워드 매칭의 한계를 극복하기 위해 pgvector와 OpenAI 임베딩을 사용하여 단어의 의미적 유사성을 기반으로 검색 결과를 도출한다.
RubyLLM과 Rails를 이용한 에이전틱 RAG(Agentic RAG) 구축 가이드
기존의 단발성(Single-shot) RAG의 한계를 극복하기 위해 LLM이 스스로 검색 전략을 결정하고 도구를 호출하는 에이전틱 RAG 구조를 채택함