You'll find this benchmarking adventure in its own blog post "Performance lessons of implementing lbzcat in Rust" https://anisse.astier.eu/lbzip2-rs.html

Performance lessons of implementing lbzcat in Rust - Linux Engineer's random thoughts
This was originally published as a thread on Mastodon. For fun I implemented lbzip2's lbzcat (parallel bzip2 decompression) clone in rust, using the bzip2 crate. Baseline: bzip2 vs bzip2-rs First, let's look at the baseline. The Trifecta Tech Foundation recently claimed that bzip2-rs had faster decompression than libbzip2's original C …
lbzip2 internally implements a full task-scheduling runtime, and splits tasks at a much smaller increments; it supports bit-aligned blocks (that are standard in bzip2 format), while my Rust implementation purposefully doesn't: I wanted to rely on the bzip2 crate that only supports byte-aligned buffers, and keep code simple (which I failed IMHO). FIN 15/15
That's it for the benchmarking! You can find my implementation at http://github.com/anisse/lbzip2-rs/ ; it's very much PoC-quality code, so use at our own risks! I chose to manually spawn threads instead of using rayon or an async runtime; there are other things I'm not proud of, like busy-waiting instead of condvar for example. 14/N

We've been running benchmarks on single CPU cores since the start. What if we unleash the parallel mode? Here are the results: lbzip2 is still much faster on the 8 cores; my implementation holds up fine, but is only 80% faster than bzip2, while running on 8 cores. On bigger files though, it starts to pay off, with up to 6.3x faster, while lbzip2 can go to 7.7x. 13/N
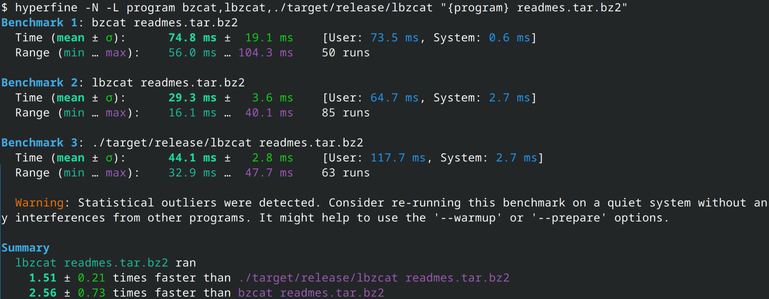
Overall, my Rust implementation (using the bzip2-rs crate) is (much) slower than lbzip2, and faster than bzip2. For some reasons, it also sees huge performance boost on performance cores, most likely due to better IPC and branch prediction. 12/N
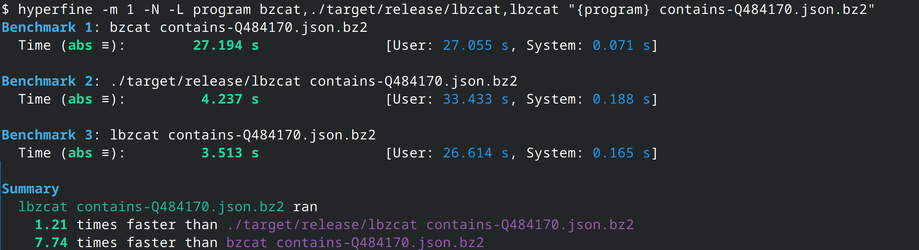
What about my implementation of lbzcat? It was designed to work with files generated by lbzip2: it does not work on some files compressed by bzip2, and silently produces incorrect output (!). So we'll limit benchmarking to files produced by lbzip2. 11/N
But wait, there is more. lbzip2 also does compression, and does so in a way that optimizes decompression. If we use a file compressed by lbzip2, it can be even faster, even on a single thread: up to 125% faster 10/N
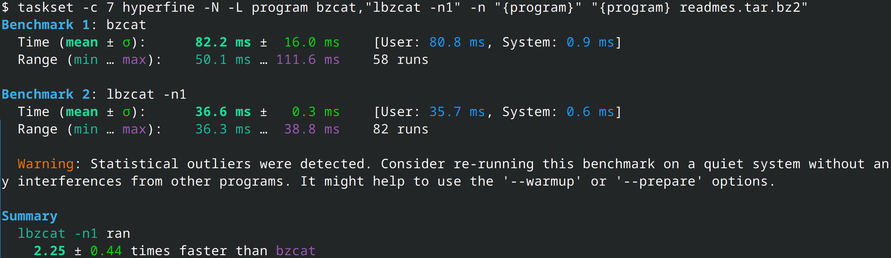
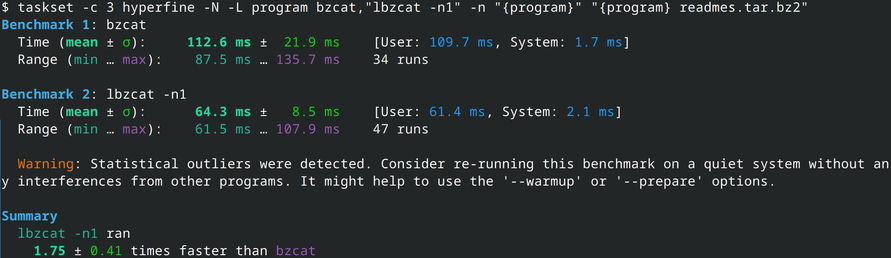
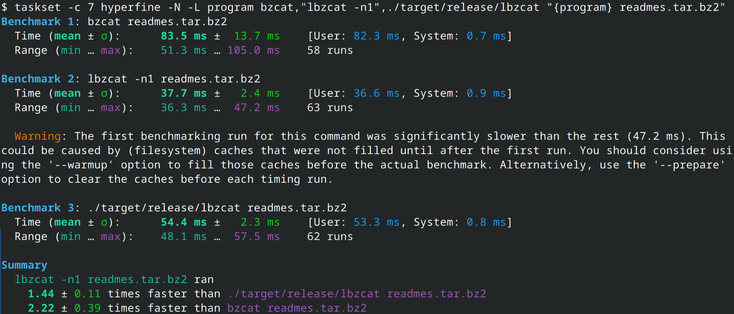
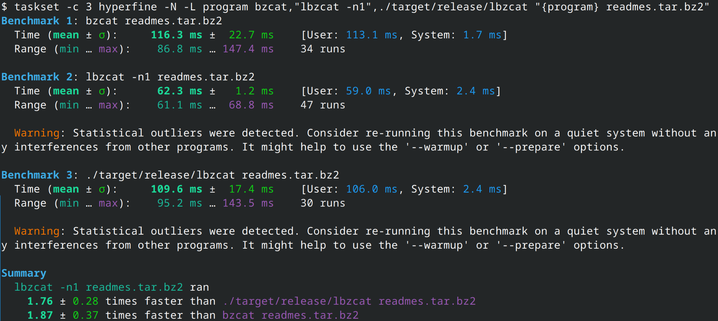
While running this, I discovered something. lbzip2's detection of the cores it can run on is... lacking: it uses the number of globally online cpu cores instead the syscall sched_getaffinity for the current process, so let's manually limit the number of processing threads: lbzip2 is now always faster, between 4% and 8%. 9/N
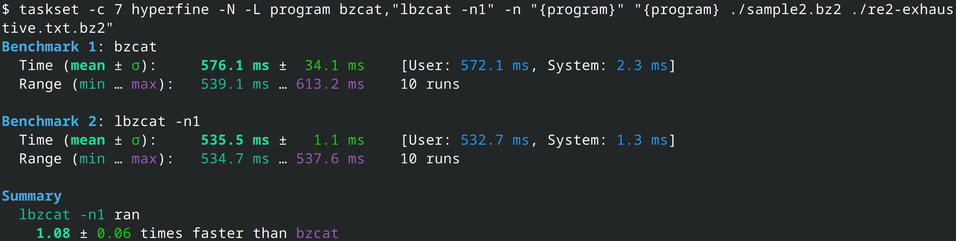
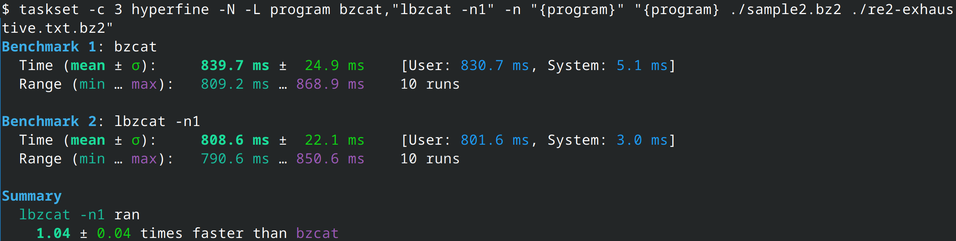
Let's have a look! Indeed, bzip2 is faster than lbzip2. Between 18% and 95% faster! 8/N
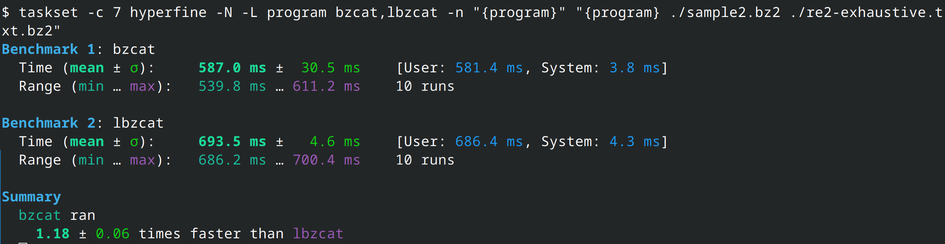
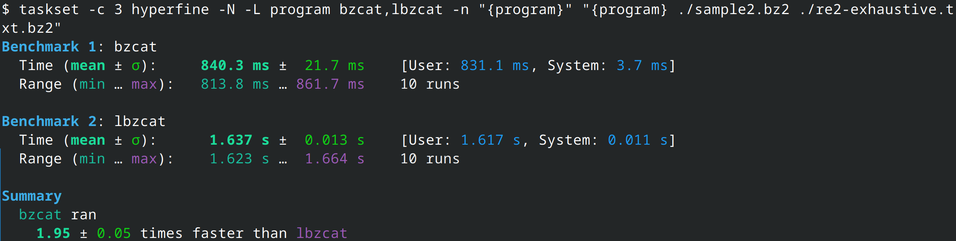
That gives us our baseline: bzip2 (in C) vs bzip2 (in Rust). But is it a fair enough comparison? I mentioned initially that I was implementing an lbzip2 "clone" (mostly a PoC for the decompression part). lbzip2 is an other program (a C binary, without a library), that can compress and decompress bzip2 files in parallel. Surely it should be slower than bzip2 since it has the parallel management overhead? 7/N