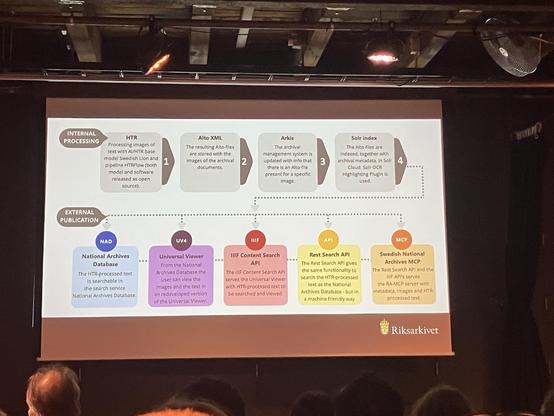
Now the Swedish National Archives talking about their journey on making the archives more accessible using #htr and #ml #lion



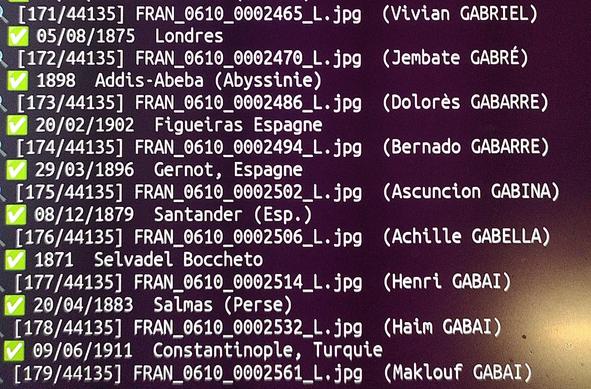
27 - Écriture
Reconnaissance automatique d'écriture manuscrite (HTR)... 
J'en reste sans voix.
#viedarchiviste #htr #HandwrittenTextRecognition #archives #workinprogress
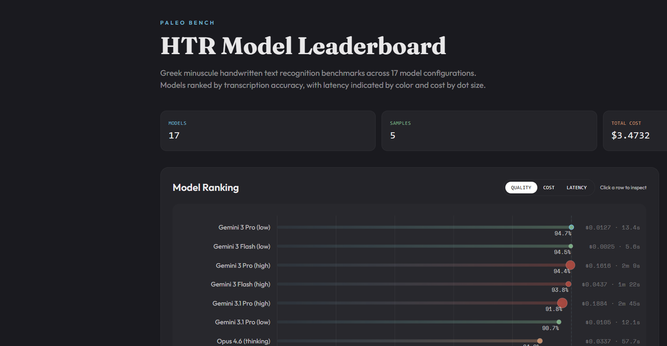
I just updated my Greek Minuscule LLM HTR Benchmark and added the latest frontier models in addition to some open weight and other models.
Some spoilers: Gemini is still far ahead for all metrics. Grok and Llama are about as bad as it gets.
In the next few months you will likely be seeing a new version of eScriptorium come to your instance. If you’re using INRIA, you may have already seen the changes. This year has brought a new milestone with major additions and improvements to eScriptorium. These updates were so significant that we had even started naming this release ‘version 1.0’, (and they are even so significant that starting version 1.0, we’ll change our naming scheme, see below).
In the next few months you will likely be seeing a new version of eScriptorium come to your instance. If you’re using INRIA, you may have already seen the changes. This year has brought a new milestone with major additions and improvements to eScriptorium. These updates were so significant that we had even started naming this release ‘version 1.0’, (and they are even so significant that starting version 1.0, we’ll change our naming scheme, see below).
Proud that we did so well in ICDAR's Competition on Multilingual Medieval Handwriting Recognition! 🥈🥉🥉
https://cmmhwr26.inria.fr/results/
Kudos especially to Viktoria Löfgren in our team for her work on this during our internal hackdays.
We hope to do more substantial work on HTR and NER for medieval Swedish, and possibly Latin, in the coming years.
Results Of the 26 registered teams, 12 submitted results, with all 12 participating in Task 1, 9 in Task 2, and 9 in Task 3. Three teams (Qianfan-OCR, STUDIUM.AI, and nampfiev1995) submitted only to Task 1. Over 300 individual submissions were recorded across the three tasks. Participants were permitted to use proprietary methods as well as additional public or non-public data beyond the competition training set. The organizers’ baseline was obtained using the kraken OCR engine with the CATMuS Medieval 1.6 model, a general-purpose recognition model for medieval Latin-script manuscripts. No further adaptation or optimization was applied for any of the tasks.
🆕🎦 New learning videos in our video course:
Reading Inventory Cards: OCR & HTR for Collection Records: https://tinyurl.com/4huphuxu by @mathias_zinnen from @SODa
SQL with Archaeological Data: https://tinyurl.com/yc6rn5hv by @fabr from @dai_weltweit
👩🎓 Learn in your own pace with any of 30 videos in our channel: https://tinyurl.com/2sexbvm9
🔜 New videos every few weeks.
#WiNoDa #OnlineCourse #Webinar #HTR #OCR #machinelearning #datascience #datacompetence #datamanagement #dataskills #SQL #archaeology