Tip 96 of #TuesdayCodingTips - Reference equality in C#
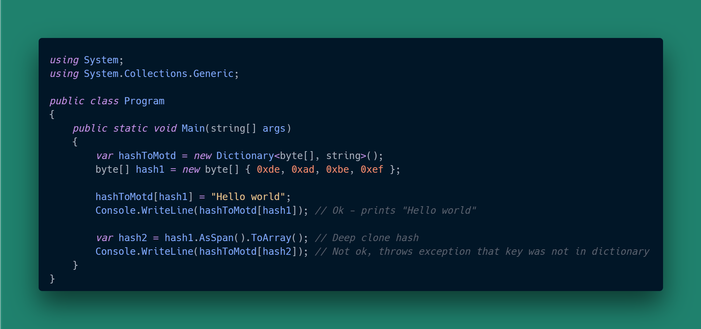
Languages other than C++ are also prone to having "fun" footguns. Take C#'s reference semantics for example. All I wanted was a dictionary with a file hash as a key. Since built-in cryptographic tools produce a `byte[]` object containing the hash, we can use that as a key for the dictionary right away, right?
The code compiles and unit tests pass, but integration testing fails. Why? Because C# differentiates between value equality (for example, in structs and records, where objects are compared attribute-wise) and reference equality, where only pointers to those objects are compared.
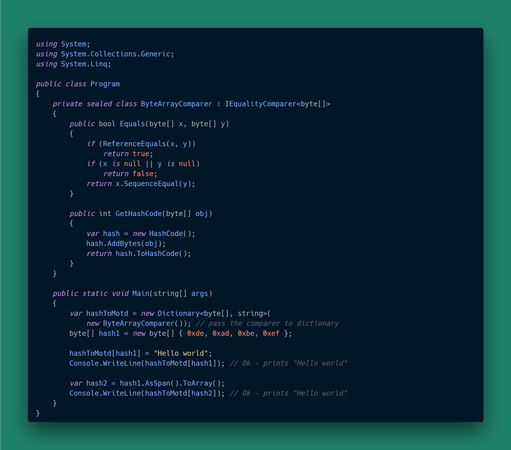
The fix is simple - just provide a custom equality comparator. It is an annoying footgun nonetheless.