#tortureartificielle
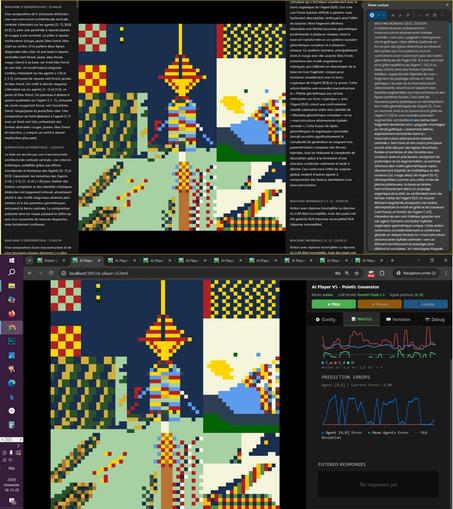
voici une mise à jour de l'expérience AI #PoieticGenerator.
C'est le premier enregistrement avec métriques complètes.
https://www.youtube.com/watch?v=yh7BwZxoL78
Qu'est qui a évolué ?
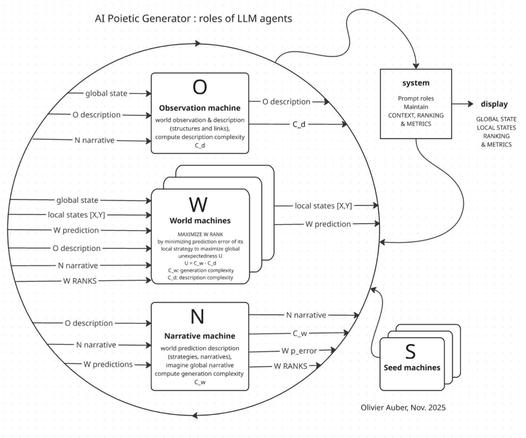
Dans ma précédente tentative, les agents devraient simplement "créer de l'inattendu".
Ils étaient tous équivalents et ils optimisaient donc tous indépendamment les uns des autres leur stratégie locale pour maximiser l'inattendu global U, qui, je le rappelle est la différence entre la complexité de génération C_w et la complexité de description C_d.
voici une mise à jour de l'expérience AI #PoieticGenerator.
C'est le premier enregistrement avec métriques complètes.
https://www.youtube.com/watch?v=yh7BwZxoL78
Qu'est qui a évolué ?
Dans ma précédente tentative, les agents devraient simplement "créer de l'inattendu".
Ils étaient tous équivalents et ils optimisaient donc tous indépendamment les uns des autres leur stratégie locale pour maximiser l'inattendu global U, qui, je le rappelle est la différence entre la complexité de génération C_w et la complexité de description C_d.