I may have posted this already, but this approximated sqrt / euclidean distance / L2 norm intrigues me a lot :)
https://klafyvel.me/blog/articles/approximate-euclidian-norm/
Kudos to @klafyvel
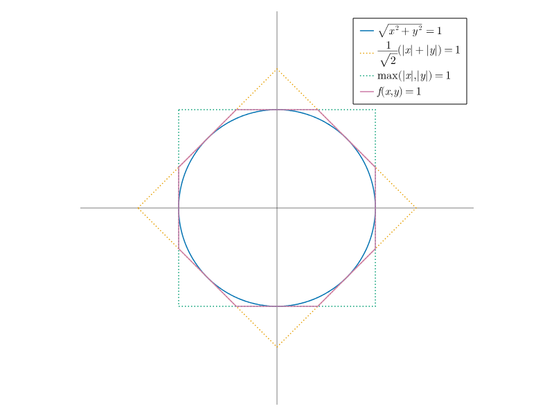
I may have posted this already, but this approximated sqrt / euclidean distance / L2 norm intrigues me a lot :)
https://klafyvel.me/blog/articles/approximate-euclidian-norm/
Kudos to @klafyvel
The #Wasserstein distance (#EMD), sliced Wasserstein distance (#SWD), and the #L2norm are common #metrics used to quantify the ‘distance’ between two distributions. This tutorial compares these three metrics and discusses their advantages and disadvantages.
🌎 https://www.fabriziomusacchio.com/blog/2023-07-26-wasserstein_vs_l2_norm/

In machine learning, especially when dealing with probability distributions or deep generative models, different metrics are used to quantify the ‘distance’ between two distributions. Among these, the Wasserstein distance (EMD), sliced Wasserstein distance (SWD), and the L2 norm, play an important role. Here, we compare these metrics and discuss their advantages and disadvantages.