RE: https://dair-community.social/@emilymbender/116604745957981805
"links will become an afterthought" is not even coded language for "the rest of the internet is merely training data and we will own the entire means of accessing information online"
RE: https://dair-community.social/@emilymbender/116604745957981805
"links will become an afterthought" is not even coded language for "the rest of the internet is merely training data and we will own the entire means of accessing information online"
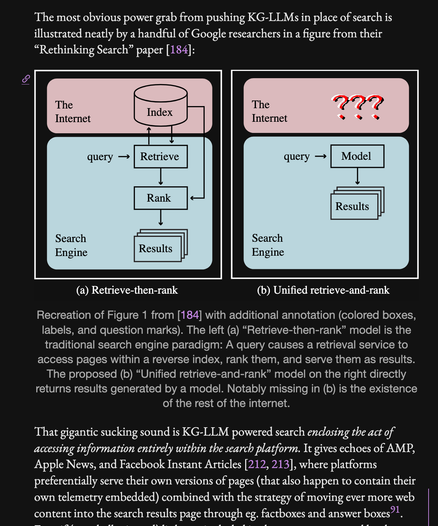
as Dr. Bender says upthread, the Rethinking Search paper just says this explicitly, also AMP, etc. I only mildly edited their figure here
The shift to "search journeys" is just another way of referring to "whole life immersive surveillance" where the intention is to slowly train you to expect more and more of your personal information to be visibly injected into search results as a surface for "personalization" and eventually move towards "zero-query search" where advertisements-i-mean-helpful-information are proactively volunteered to you.
this language appears in full form as early as 2018 and was chilling even then:
The zero-query search paradigm can be expressed with the slogan “the query is the user.” In practice, the context of the user is used to infer information needs. (Entity Oriented Search)
There IS NO LLM USE not associated with the project to seize all information as a product. That is the WHOLE gamble being made that is driving all those billions into getting as many people as possible dependent on the most preposterously expensive and inefficient model of computing ever devised. It is only worth it if the upside is owning the whole economy.
Every step you take towards building LLMs into your daily habits and work ratchets the spring tighter on the mousetrap until, surprise! It clamps shut while your whole ass is wrapped around the cheese. Don't make me laugh with local models nonsense, if you think that those don't get deprecated the moment they pose the slightest whiff of a threat to the profit model - meta isn't releasing weights to be nice, it's to capture labor and control the tooling space. Don't be a sucker.
@starsider
Historically corporate open source projects have served the role of concentrating free labor as a way to drive the shape of how a given kind of thing within a tool domain is done. Its a win-win-win for them: buy goodwill towards the brand, get people to build your product for free, prevent your competitors from doing the same and potentially excluding your competing business model through technical means. Chrome/chromium is the most obvious example - by maintaining (and thus controlling the design of) an ostensibly open source project, Google gets de facto control over web standards, its an extremely powerful weapon.
Local models are similar, google was famously freaked out by this when llama was released (it was only meta's incredible capacity to literally fumble everything it has ever done aside from Facebook Zero and the news feed that killed that advantage). It doesn't really matter which non-google/openai/anthropic company is doing it the pattern is the same. Tool harnesses are fit to the model and its api. In every LLM wrapping package you see a set of decisions around which models API, calling conventions, and features to support.
E.g. OpenAPI provides a "structured output" mode that is, in all likelihood, a server side version of how anthropic does it clientside: just bash the LLM against JSON schema until it passes validation. Tools that make use of that feature will either not support or second-class your API or model if you don't have it. So even though a feature like structured output is probably just an API artifice rather than a real "feature" it can serve as a decision point for whether something uses your model or not, and that's a strategic opportunity. (I'm just using structured output as an example because anthropic's version of it is so funny, I don't have any specific info about it being a wedge feature or not. The principle applies to any design feature). I don't have numbers, there is a lot of direct b2b from the AI companies, but integrations are big money.
So if you are behind in subscription market share, you can release an open source model and stay in the game in the tooling space. If you become popular, you can become "must support" - every tool written now must be able to call Claude and openAI, if you can't, your shit sucks. Then you can start jostling around the surrounding tooling space and see who you can pick off. The tech nerds who are very into "openness" will code for you and push for your model to be supported by whatever integration, and we're back to the classic model of corporate open source being a concentrating point for free labor and goodwill.
@jonny I still don't quite follow your line of reasoning. Tools made for claude and openai have been made regardless of them releasing open models or not. Claude hasn't released any open model, and openai only released a couple at the same time with pretty much the same compatibility with existing tools as other models. The only reason to release models is for good PR, not for the community to make tools: they already do for cloud models. Which is why I haven't tried almost any of them: if I can't try them easily with a local model I ignore them. I don't want AI companies to even know that I exist. I feel like local-only tools exist in a different world (of a community that uses LLMs mostly for personal entertainment purposes and not for serious stuff, which incidentally is also where my interest in LLMs lie).
Except for ollama, which I think is a trojan horse: it's "convenient" but shit at running local models and even more conveniently you can run cloud models through their online service.
@starsider
That's a reasonable attitude, but say you were just a normal LLM user who is fine with using the closed models.
Rewind back to 2023 before meta bungled it, back to when they bungled it in a different way after llama leaked. Google leaked a memo then: https://newsletter.semianalysis.com/p/google-we-have-no-moat-and-neither
Paradoxically, the one clear winner in all of this is Meta. Because the leaked model was theirs, they have effectively garnered an entire planet's worth of free labor. Since most open source innovation is happening on top of their architecture, there is nothing stopping them from directly incorporating it into their products.
The value of owning the ecosystem cannot be overstated. Google itself has successfully used this paradigm in its open source offerings, like Chrome and Android. By owning the platform where innovation happens, Google cements itself as a thought leader and direction-setter, earning the ability to shape the narrative on ideas that are larger than itself.
Now things haven't shaken out exactly like that, and the consumer wrappings and harnesses have proven more important than the weights so far. Heavy users are using all of them, and there is some smaller proportion of people who hop between models, but say the open weight models did gain some appreciable user share. Anthropic wants their moat, they want to keep Claude code locked to Claude models, but if there was appreciable open model use with some open harness, something like openclaw but less ridiculous, then that could force their hand to allow subscription use with a different tool. If you're a company releasing open weights, you're behind, you've taken money out of your competitors product and shallowed out their moat already.
Now say you start to pick up steam, and you start to release some models with some special API features people like, now you've put the hosted model providers on a back foot, and they have to adapt and provide them or lose users. Now you're using your open models to steer tooling as a weapon. You're building up a set of integrations fit to your special API shape and it becomes increasingly difficult to retrofit to Claude. In the optimistic case, your open model has dictated the form that LLMs must take, and you have room to play with freemium weights and corporate licenses and so on.
This is already starting to happen with the moonshot and deepseek models, e.g. look at openrouter stats: https://openrouter.ai/rankings
And will probably continue as they have to ratchet up prices and usage limits. With open weight models these companies are in a good position to pick up the price defectors and steer them into their own ecosystems. The goodwill and tooling and ecosystem ownership all work hand in hand as complementary methods to fight for control of the space.