Alle die nichts über #ki und #llm lesen wollen, bitte kurz abschalten, da ich mal über GPT-5.5 Pro reden muss.
Dieses Modell überrascht uns in der #Mathematik gerade ziemlich.
Ein länglicher 🧵
Alle die nichts über #ki und #llm lesen wollen, bitte kurz abschalten, da ich mal über GPT-5.5 Pro reden muss.
Dieses Modell überrascht uns in der #Mathematik gerade ziemlich.
Ein länglicher 🧵
Letzte Woche fand der Workshop "Benchmarks in Leipzig" statt (ratet mal wo) und kurz gesagt: Es fällt selbst Profi-Mathematiker:innen mittlerweile sehr schwer, innerhalb von, sagen wir, ein paar Stunden eine Forschungsfrage mit klarer, ihnen bekannter Antwort aufzuschreiben, die dieses Modell nicht lösen kann.
https://www.mis.mpg.de/de/events/series/benchmarks-in-leipzig
OK, jedes Benchmarking findet in einem Framework statt, das bestimmte Fragen ausschließt und nur kleine Teile der Mathematik abbildet. Vorweg: Mathe ist noch lange nicht gelöst oder erledigt!
In Leipzig kam Science Bench von @ChristianStump zum Einsatz. Da sind z.B. keine Ja/Nein-Fragen erlaubt, kein "Finde den Beweis von ..." und noch ein paar weitere Einschränkungen.
Christians Draft-Seite zum Thema "Mathe gelöst" übrigens
https://math.sciencebench.ai/definition-theorem-proof
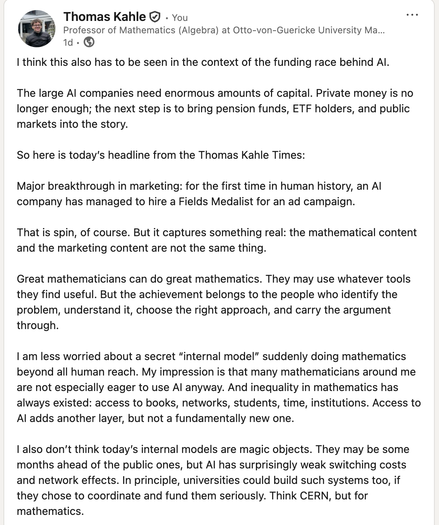
Die einhellige Meinung von allen, die es wirklich ausprobieren: GPT-5.5 Pro ist den anderen Modellen weit enteilt. Die Zahlen sagen das, und beim Ausprobieren merkt man es auch.
Hier sind die Benchmarks der Probleme von Christian:
https://math.sciencebench.ai/benchmarks
Aber Pro ist hier noch NICHT aufgeführt und es löst nochmal einen ganzen Schwung weitere Fragen.
Aber was ist dieses GPT-5.5 Pro?
Früher haben wir mal immer gewitzelt (im Bezug auf Apple): Pro means showing up to your meeting with a bunch of dongles.
Im Ernst: GPT-5.5 ist eine Modellfamilie von OpenAI, die schon sehr stark ist. Pro ist ein etwas verstecktes Modell darin. Im normalen Plus-Abo der App kann man es nicht auswählen, man braucht mindestens den "Pro"-Zugang, also den für ca. 100$ im Monat oder mehr.
Die Webapp ist natürlich unbequem. Über die API kann man es auch nutzen, und es ist SCHWEINETEUER: 180$ pro 1M Token Output.
Zum Vergleich: Das gemeinhin als teuer geltende Opus 4.7 kostet 24$, ein großes OS-Modell (> 1T Param.) wie DeepSeek V4 Pro 85 Cent.
In CODEX, dem Coding-Harness von OpenAI, kann man Pro auch nicht per Monatsabo nutzen. Ergäbe aber auch wenig Sinn: Das Modell braucht extrem lange zum Antworten. Mathe-Frage reingeben und 1-2h auf die Antwort warten ist komplett normal.
Was ist das jetzt? Hat OpenAI eine neue geheime Sauce erfunden? Haben sie die Skalierung nochmal auf 11 gedreht, und deswegen ist es so teuer und langsam? Ist das das eigentliche Foundation Model, und GPT-5.5 schon eine Destillation davon?
Warum bewerben sie "nur" GPT-5.5 und fast gar nicht Pro? Auf OpenAIs eigener Benchmark-Seite taucht es in der Tabelle auf, und auch da ist es Spitzenreiter bei den Mathe-Benchmarks.
Hier eine Theorie, die vielleicht Quatsch ist, aber who knows: GPT-5.5 Pro ist gar kein einzelnes LLM. Sie spawnen im Hintergrund mehrere Agents, die als Team (mit normalem GPT-5.5 als LLM) eine ausgefeilte Recherche durchführen, ein gewisses Token-Budget verbrauchen und am Ende einen Report rausgeben!
Dann würden die Benchmarks aber ziemlich Äpfel mit Birnen vergleichen, denn ein Opus Agent Team ist bestimmt auch nochmal besser als nur Opus.

Klar erkennbar ist: OpenAI hat sich stark auf die (Mathe-)Benchmarks konzentriert und optimiert systematisch darauf hin. Das ist ihr Marketing-Play.
Anthropic setzt auf Coding und hat deshalb den Stunt mit Mythos gemacht.
Mythos ist wahrscheinlich auch so eine Art "Opus 4.7 Pro", aber Anthropic hat schlicht nicht die Hardware, um das der Allgemeinheit anzubieten.
Schlussgedanke 1: Die Zeit der Benchmarks kann sehr schnell vorbei sein. Es ist für Menschen einfach zu schwer und zu mühsam, noch Mathe-Fragen per Hand zu generieren, die sie selbst lösen können und LLMs nicht. Der Trend geht dahin, direkt an Open Problems zu arbeiten.
Dann hat man natürlich wieder das Problem, dass kein Mensch die Outputs lesen will. Wir müssen den Social Contract neu schreiben, damit wir uns nicht an korrekten, aber ungekochten (wie @tao sagen würde) Beweisen verschlucken.
Und 2: Was haben die Firmen, das wir in der Uni nicht haben? Geld sicher. Aber auch mehr menschliche Intelligenz? Mehr Erfahrung? Freiheit für Kreativität? Weniger Bürokratie?
Ehrlich gesagt haben wir LLMs einfach auch sehr sehr lange belächelt und ignoriert. Jetzt sollten wir in der Uni mal wieder in die Pötte kommen und wenigstens an der Open-Science- und Open-Weights-Front aufholen.
Ende.
@tomkalei Ja, Geld; für Hardware und Strom, aber auch Gehirn.
Während wir an den Unis viele Doktorandys breit ausbilden können sich die großen LLM-Firmen dann die fünf, sechs Top-Ausgebildeten pro Monat kaufen.
Die nutzen einfach die Forschungsergebnisse. Für das Training von LLM auch einfach mal ohne irgendwem was für die Daten zu bezahlen.
Sie haben ne Menge Geld und keine Skrupel zu klauen und zu betrügen.
Nein, so kann man nicht argumentieren. #OpenScience ist super wichtig. Die aus Steuern finanzierten Forschungsergebnisse müssen frei verfügbar sein, ohne Lizenzgebühren oder Einschränkungen und auch für Firmen. Da kämpfen wir seit Jahren drum.
Das Besitz-Argument kann von mir aus auf alle Romane und Kunstwerke angewendet werden, aber nicht auf Forschungsergebnisse von öffentlichen Unis und schon gar nicht in Mathe (Mathe = Wahrheit und damit nicht patentierbar).
@tomkalei Ja, auch …
Erklärt BigTech „dem Steuerzahler”, wo die Grundlagengorschung herkam?
Zum Training der LLMen ist aber neben „so sehen logische Beweise aus, lerne implizit die Regeln zur korrekten Hintereinanderschreibung von Quantoren etc” auch natürlichsprachliche Korpora, ergo geklaute Romane, notwendig.
Bzw. die gekauften reddit- und stack overflow-Datenbanken. Plus die offene Wikipedia.
@TheOneSwit
@tomkalei Insofern finde ich auch nicht, dass Unis diesen Wettlauf um jeden Preis und ohne Rücksicht auf Verluste unbedingt mitmachen sollten.
An LLMs forschen natürlich schon (passiert ja auch), aber vielleicht doch mit etwas mehr Nachdenken und Hinterfragen, was genau man da eigentlich tut.
Und in dem Bereich wiederum haben Universitäten dann vielleicht doch gewisse Vorteile im Vergleich zu Unternehmen, deren Investoren baldige Milliardengewinne erwarten...
Und baldige Gewinne scheinen die Investoren ja auch nicht zu erwarten, denn Anthropic und OpenAI wollen die ganze Zeit immer nur noch mehr Geld und versprechen überhaupt kein break even mehr vor 2030 oder noch viel später.
Ist ein Punkt, allerdings denke ich nicht, dass die Ethikkommission jemals in der Mathematik oder Informatik reinschaut, aber wer weiss.
Ich schreibe nochmal was Ernsthafteres mit @ChristianStump zusammen dazu auf.
Kurz gesagt: Für mich ist die Welt _keine_ andere als am Tag davor, aber am Tag davor war sie auch schon ziemlich crazy. Ich finde das AlphaEvolve Paper wichtiger als dieses von OpenAI, aber das kann man diskutieren.
https://machteburch.social/@tomkalei/116610786332140016
Ansonsten poste ich ja hier gefühlt sowieso die ganze Zeit, was ich zu KI in Mathe denke.
Have you seen this big success of openAI's marketing? For the first time in history they managed to hire a Fields medallist for one of their Ad videos! https://openai.com/index/model-disproves-discrete-geometry-conjecture/
@tomkalei Vorhin hatte ich im „normalen“ 5.5 in Codex einen Prompt, an dem 27 Minuten gearbeitet wurde. Die Aufgabe wurde vollständig gelöst, mit mehreren Syntaxchecks, Patches und Testbench zwischendurch (alle schön ins git eingepflegt).
Hat 30% der Credits-pro-5-Stunden im 20 €-Abo gekostet.
Wie krass muss dann „Pro“ sein.
Ich freue mich auf den Tag, wo das ehrlich bepreist wird. Dann können wir eine "Kosten-Nutzen-Gesamtrechnung" machen.
Allerdings für Wissenschaft: Mal unter der Annahme, dass die Gesellschaft noch Wissenschaft will, ist das alles noch im Rahmen, z.B. im Vergleich zum Bau und Betrieb des DESY.
Diese Riesenmodelle sind für die Mathematik sowas wie Teilchenbeschleuniger, oder?
@tomkalei @sci_photos @Marcel Abwarten. Mich erinnert das an zwei Dinge:
a) Das GHz-Rennen um 2000. Da wurden auch absurde Sachen gemacht, die abgefahren aussahen, aber in der Praxis null Wirkung hatten, weil es alles synthetisch war[1].
b) Deep Blue / AlphaGo. Sicher beeindruckend, dass man Schach und Go "lösen" konnte, aber auch ein Vergleich 20W <-> 200(!) kW.
@tomkalei @sci_photos @Marcel [1] Damit will ich nicht sagen, dass Plus nur ein Benchmark-Breaker wäre, ich sehe auch Sachen, von denen ich echt nicht gedacht hätte, dass Transformer das könnten.
Meine Intuition ist aber, dass es ein bisschen so in Richtung Hidden Subgroup Problem geht: Benchmarks, die man sich überlegt sind eben lösbar, weil man in der Problemstellung eine ganze Menge mitgibt.
@tomkalei @sci_photos @Marcel Will sagen: In Summe und mit echten Preisen ist das vielleicht etwas, das gerade so ökonomisch ist.
Am Ende ist es aber so, dass man mit Abstrakter Mathematik allein Billiarden an Investitionen nicht wieder hereinholen wird, denn für Nudelsalatrezepte und Teenagerpsychosen bezahlt man halt keine hunderte Dollar im Monat - und dann friert quasi der Stand jetzt erstmal ein.
@tomkalei @sci_photos @Marcel Ein weiterer Punkt: Was verbindet Coding und Mathematik?
Dass es hochformalisierte Probleme sind, die praktisch volldigitalisiert vorliegen.
Das kann man von KEINEM anderen Problemfeld in der Form sagen - und deshalb bin ich total sicher, dass man sich darauf stürzt - OpenAI Mathe und Anthropic eben Coding.
Unstrukturierte Daten auf RLHF zu formen ist absolut BRUTAL und skaliert be...scheiden.
@tomkalei @sci_photos @Marcel Zurück zu AlphaGo: Wir wissen lange, dass viele Probleme lösbar sind, wenn man nur genug[tm] Compute drauf wirft und ich meine, dass Coding und Mathe eben die beiden Bereiche sind, wo das bis zum Ende gemacht wird.
Im Grunde kann man daraus auch die Verzweiflung der Anbieter ablesen: Würden andere Sachen "gut" funktionieren, müsste man sich nicht auf Nischen im Gesamtproblemraum[2] konzentrieren.
Es gibt hier überhaupt keinen Netzwerkeffekt. Wenn du von WhatsApp zu Signal wechselst ist da erstmal keiner deiner Freunde und die App ist wertlos für dich. Wenn du von einer KI zur anderen wechselst antwortet die halt vielleicht in einem anderen Tonfall oder hat andere Probleme, aber das auf dem Level "neue App".
Es gibt höchstens einen Lock-In (Abhängigkeit) von KI im Allgemeinen, aber es gibt halt auch Bier bei der Getränkefeinkost für 7 EUR oder beim Aldi für 59 Cent.
Naja genau.
Bei OpenRouter kannst du sehen was der Betrieb wirklich kostet. DeepSeek Pro für „billo“ ist für 99,5% der Anwendungen genug.
Ich trinke auch nicht zu jeder Mahlzeit Champagner. Meistens muss Crémant genügen!!
AlphaFold und verschiedene Optimierungstools wie AlphaEvolve kann man auch noch nennen. Das sind schon Durchbrüche. Aber eben viel menschliche Genialität plus Compute.
Aber das war schon immer so. Wir standen on the shoulder of the technology giants.
Und ich meine die Technologie nicht die Bros.