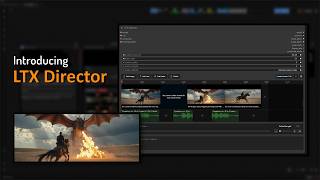
shootthesound/comfyui-mesh: Split FLUX.2 and LTX 2.3 across two GPUs (LAN or same-machine) — NVENC compresses activations live on the wire. Icarus (ComfyUI node) + Daedalus (back-half server).
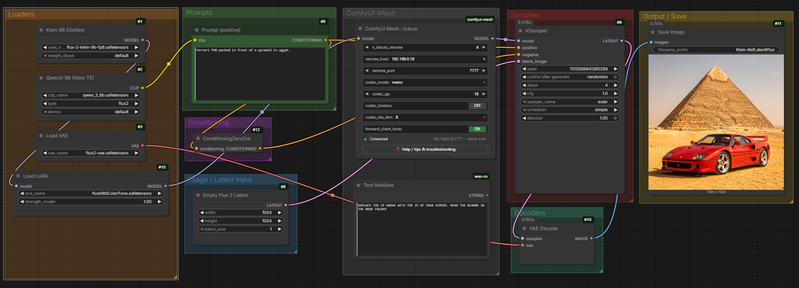
FranckyB/Voice-Clone-Studio-DramaBox: A simplified DramaBox version of Voice Clone Studio. Allows for Lora Generation that can also be used in ComfyUi.
FranckyB/ComfyUI-DramaBox: Port of resemble-ai's DramaBox for ComfyUI
Is there any simple tutorials for regional promping , for only 2 characters (regions ) that will have different loras ? I am using the Comfyui
Is there any simple tutorials for regional promping , for only 2 characters (regions ) that will have different loras ? I am using the Comfyui - Divisions by zero
Is there any simple tutorials for regional promping , for only 2 characters (regions ) that will have different loras ? I am using the Comfyui
New Open-Source Models Now in ComfyUI: VOID, BiRefNet & Gemma 4

Forgetting on Purpose: Generalization as the Quality Criterion for Small-Dataset LoRA Fine-Tuning
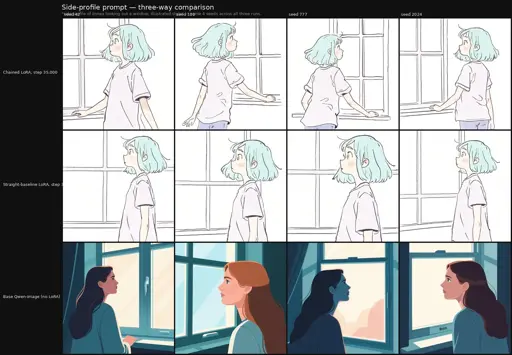
Forgetting on Purpose: Generalization as the Quality Criterion for Small-Dataset LoRA Fine-Tuning - Divisions by zero
# Abstract >A LoRA that reproduces its training images perfectly is not a well-trained model. It is a memorization device. This article argues that generalization within the trained concept is the right quality criterion for small-dataset LoRA fine-tuning, and proposes a five-tell diagnostic framework — base capability degradation, concept narrowing, caption rigidity, entanglement leak, and visual signature reproduction — for identifying when a LoRA has crossed from learning into memorization. We then describe a chained training schedule we use in our own work, which rotates through dataset subsets before reintroducing the full combined dataset for a final consolidation phase. This methodology has roots in early Stable Diffusion 1.5-era practitioner trainers, where dataset switching was first-class in the UI; in modern trainers it must be reconstructed manually. We report a paired A/B run on Qwen-Image at two scales — a 244-image illustration style LoRA and a 27-image character LoRA — comparing chained training against a monotonic straight-baseline twin under matched conditions. Both runs produce competent results that pass the five-tell diagnostic without obvious failure on either side, and the hyperparameter recipe we use proves itself viable for Qwen-Image at these scales. We observe specific signals of chained-side flexibility advantages, but the gap is not dramatic enough at these dataset sizes to claim a general methodological advantage from this experiment alone. The natural next test is at smaller and harder dataset sizes where overfitting is more likely to surface; we identify that as the experimental program this position paper opens onto rather than closes.
Pixal3D: Pixel-Aligned 3D Generation from Images
Pixal3D: Pixel-Aligned 3D Generation from Images - Divisions by zero
# Abstract >Recent advances in 3D generative models have rapidly improved image-to-3D synthesis quality, enabling higher-resolution geometry and more realistic appearance. Yet fidelity, which measures pixel-level faithfulness of the generated 3D asset to the input image, still remains a central bottleneck. We argue this stems from an implicit 2D-3D correspondence issue: most 3D-native generators synthesize shape in canonical space and inject image cues via attention, leaving pixel-to-3D associations ambiguous. To tackle this issue, we draw inspiration from 3D reconstruction and propose Pixal3D, a pixel-aligned 3D generation paradigm for high-fidelity 3D asset creation from images. Instead of generating in a canonical pose, Pixal3D directly generates 3D in a pixel-aligned way, consistent with the input view. To enable this, we introduce a pixel back-projection conditioning scheme that explicitly lifts multi-scale image features into a 3D feature volume, establishing direct pixel-to-3D correspondence without ambiguity. We show that Pixal3D is not only scalable and capable of producing high-quality 3D assets, but also substantially improves fidelity, approaching the fidelity level of reconstruction. Furthermore, Pixal3D naturally extends to multi-view generation by aggregating back-projected feature volumes across views. Finally, we show pixel-aligned generation benefits scene synthesis, and present a modular pipeline that produces high-fidelity, object-separated 3D scenes from images. Pixal3D for the first time demonstrates 3D-native pixel-aligned generation at scale, and provides a new inspiring way towards high-fidelity 3D generation of object or scene from single or multi-view images. Project page: this https URL [https://ldyang694.github.io/projects/pixal3d/] Paper: https://arxiv.org/abs/2605.10922 [https://arxiv.org/abs/2605.10922] Code: https://github.com/TencentARC/Pixal3D [https://github.com/TencentARC/Pixal3D] Model: https://huggingface.co/TencentARC/Pixal3D [https://huggingface.co/TencentARC/Pixal3D] Project Page: https://ldyang694.github.io/projects/pixal3d/ [https://ldyang694.github.io/projects/pixal3d/] [.png] [.png] [.png] [.png]

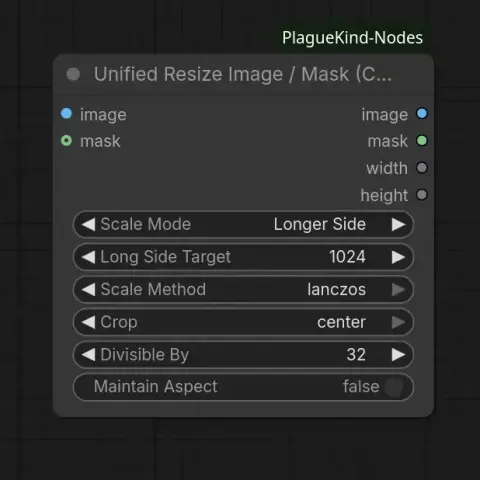
PlagueKind/ComfyUI-PlagueKind-Nodes: ComfyUI custom node providing unified image and mask resizing
WhatDreamsCost/WhatDreamsCost-ComfyUI: All-In-One Timeline Editor. I2V, T2V, FLFF, Prompt Relay, Custom Audio, and more!