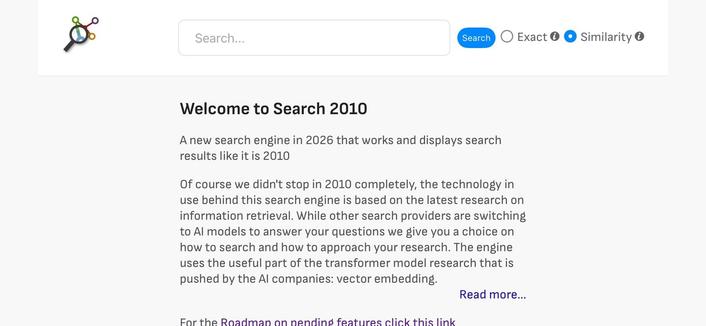
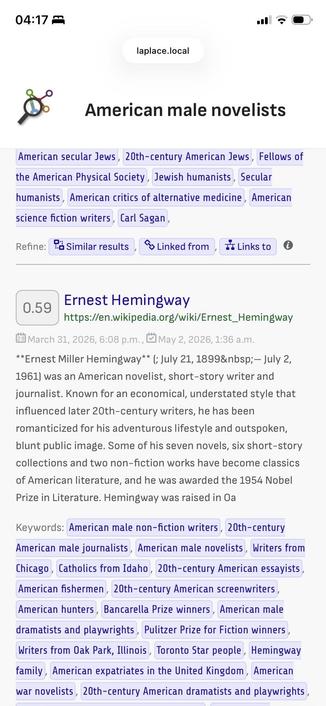
Search engine project seems possible with the research I have done. What it should be in the end is something like a Google search as it was before they kicked "don't be evil" from their claim. No ads, just search results but enhanced with modern technology. I want to have some kind of "Research Mode" as well, so you could decide if you want exact matches (full text search) or similar items (vector search) and then based on the search results "drill down" into a result to find similar results to the selected one (or stuff that links there, etc.)
Plan for deployment of the Search Engine is to keep the index on a shared PostgreSQL cluster and have some crawler nodes with additional crawlers hosted by community. Frontend could be expanded by community hosted instances as well, the base implementation will basically be an API and a basic search frontend.
For vector embedding I think it would make sense doing it "Folding at Home"-Style, basically only do the full text indexing on the PostgreSQL server and run (possibly GPU enabled) worker processes to do the embedding on nodes provided by the community (in addition to some slow CPU only inference on the server).
So you could basically run a inference node on your desktop which would use the compute power of your GPU to provide vector indexing compute resources to the search engine "to give back" something or provide crawler nodes to spread the load. The search itself does not need GPU, just the indexing.
Would you contribute to such an effort?
#diySearchEngine